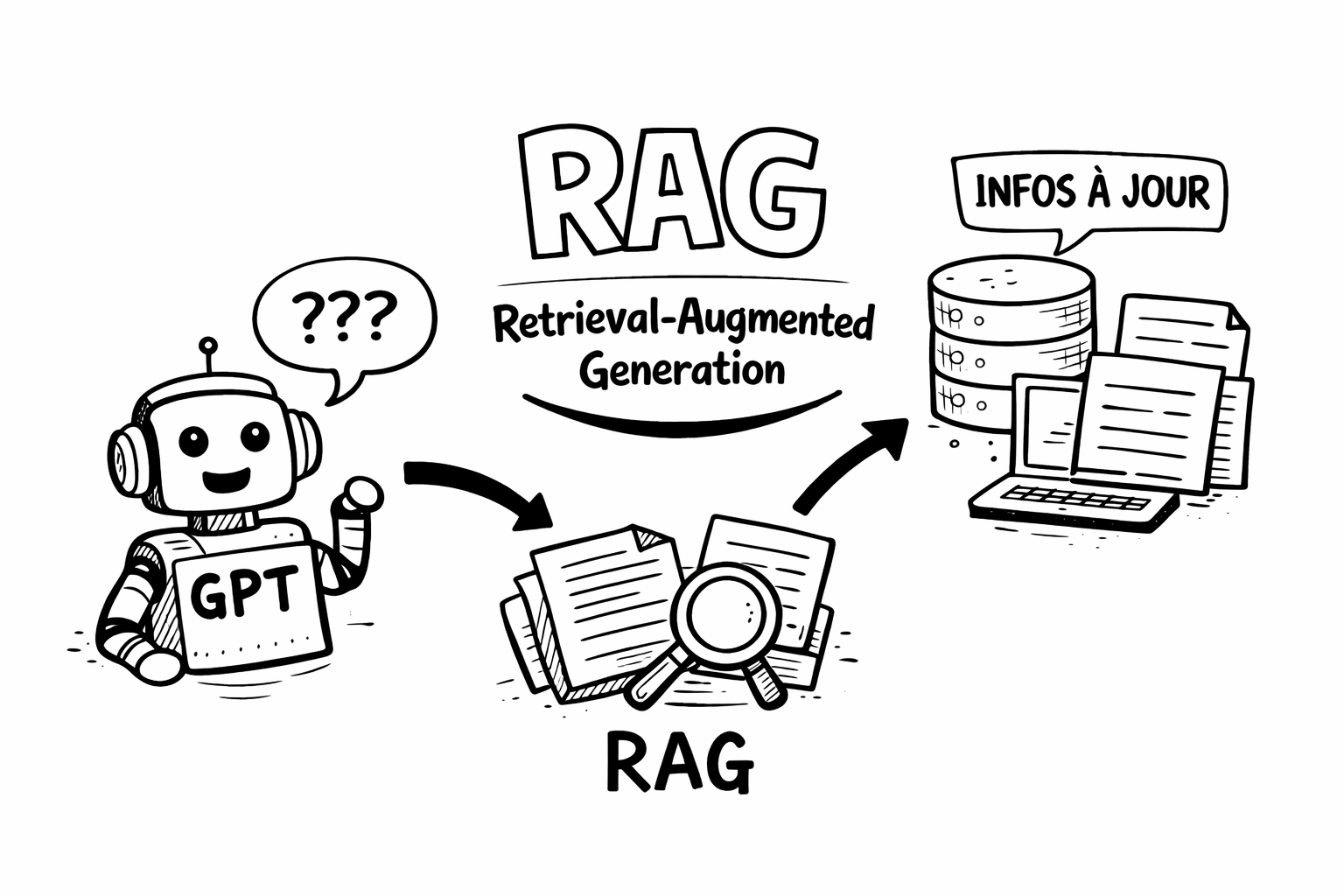
Les modèles de langage comme GPT, BERT ou LLaMA ont révolutionné notre manière d’interagir avec les machines. On parle à présent d’intelligence artificielle générative (GenAI). Pourtant, une limite importante persiste : ces modèles ne peuvent pas accéder à des données en temps réel après leur entraînement. Conséquence ? Ils peuvent halluciner, donnant parfois des réponses totalement incorrectes par faute de source actualisée.
C’est là qu’intervient le RAG (Retrieval-Augmented Generation), une approche hybride combinant génération de texte et récupération intelligente d’informations. Grâce au RAG, les modèles peuvent enrichir leurs réponses avec des données externes, pertinentes et souvent en temps réel.
Dans cet article, nous allons explorer ce qu’est le RAG, comment il fonctionne, comment il se distingue des modèles classiques, et quels sont ses cas d’usage dans le monde professionnel.
Qu’est-ce que le Retrieval-Augmented Generation (RAG) ?
Le Retrieval-Augmented Generation, ou RAG, est une approche d’intelligence artificielle qui combine deux techniques :
- La recherche d’information (retrieval) dans une base de données externe.
- La génération de texte (generation) à partir des résultats trouvés.
Autrement dit, au lieu de compter uniquement sur sa mémoire interne (comme les modèles classiques), un modèle RAG interroge une source externe — documents, articles, bases internes — pour produire une réponse plus précise et contextualisée.
Le terme a été introduit en décembre 2020 par Facebook AI (Meta) dans un article scientifique qui décrivait une méthode permettant à un modèle de générer des réponses en s’appuyant sur des documents pertinents retrouvés dans une base vectorielle.
Fonctionnement du RAG : génération augmentée par la recherche
Un système RAG suit généralement quatre grandes étapes :
- Encodage de la requête : Le texte de l’utilisateur est converti en vecteur via un modèle d’embedding.
- Recherche de documents : Ce vecteur est comparé à ceux d’une base de données vectorielle pour retrouver les documents les plus proches sémantiquement.
- Fusion de contexte : Les documents retrouvés sont intégrés comme contexte dans la requête.
- Génération de réponse : Le modèle de langage utilise ce contexte pour formuler une réponse plus précise.
Ce fonctionnement est souvent comparé à un assistant qui consulte une base documentaire avant de répondre à une question. L’objectif : améliorer la précision, la pertinence et l’actualité des réponses générées.
Quelle différence entre RAG et les modèles de langage traditionnels ?
Les modèles classiques comme GPT-4 sont autonomes : ils génèrent des textes en s’appuyant uniquement sur leur entraînement préalable. Ils ne savent pas aller chercher une information externe.
À l’inverse, un système RAG est connecté à une source d’information vivante : il peut s’appuyer sur une base documentaire, un index vectoriel ou même des API en temps réel.
| Fonctionnalité | LLM Classique | Modèle RAG |
|---|---|---|
| Accès à des données externes | ❌ | ✅ |
| Mise à jour possible sans réentraînement | ❌ | ✅ |
| Hallucination d’informations | Fréquente | Réduite |
| Personnalisation métier | Limitée | Élevée |
En résumé, le RAG est plus flexible, plus fiable et plus actualisable que les LLM seuls.
Quelles sont les applications concrètes du RAG ?
Le RAG ouvre la voie à de nombreuses applications en entreprise et dans la recherche, notamment :
- Support client : Un chatbot peut s’appuyer sur de la documentation pour répondre précisément aux questions des utilisateurs.
- Assistance documentaire : Pour les secteurs réglementés (juridique, médical, financier), le RAG permet de consulter des bases de connaissances précises.
- Recherche scientifique : Consultation de bases de publications pour formuler des résumés ou hypothèses.
- Knowledge Management interne : Valorisation de l’archivage d’entreprise (notes, rapports, emails, etc.) pour l’aide à la décision.
- Moteurs de recherche augmentés : Par exemple, Bing (Microsoft) utilise des mécanismes similaires pour enrichir les résultats de recherche avec GPT.
Quels sont les avantages et les limites du RAG ?
Avantages :
- Réponses plus précises grâce à l’accès à des sources ciblées.
- Réduction des hallucinations en citant les sources fiables.
- Adaptabilité : il peut s’adapter à n’importe quelle base documentaire.
- Actualisation simple : inutile de ré-entraîner le modèle, il suffit de mettre à jour la base de connaissances.
Limites :
- Qualité des sources : si la base documentaire est mauvaise, les réponses le seront aussi.
- Complexité technique : nécessite un moteur de recherche vectorielle, un pipeline d’intégration et des infrastructures adaptées.
- Latence : la récupération des documents peut allonger le temps de réponse.
- Sécurité : il faut gérer l’accès aux données sensibles dans l’entreprise.
Conclusion : le RAG, une nouvelle génération d’IA augmentée
Le RAG représente une nouvelle manière d’utiliser les systèmes d’IA générative. En permettant aux modèles de langage de s’appuyer sur des bases documentaires externes, il combine le meilleur des deux mondes : la puissance de la génération de texte et la rigueur de la recherche d’information.
Dans un contexte professionnel, il ouvre des perspectives concrètes pour créer des IA plus fiables, plus à jour et mieux personnalisées. Le RAG permet aux entreprises de capitaliser sur leur propre savoir tout en profitant des dernières avancées des outils d’intelligence artificielle générative.
FAQ sur le RAG
Le RAG est-il utilisé dans ChatGPT ?
Indirectement oui. Par exemple, ChatGPT peut intégrer des outils de recherche via des plugins, API ou extensions internes.
Peut-on créer son propre système RAG ?
Oui, avec des outils comme LangChain, Haystack, Pinecone, ou encore Elasticsearch + OpenAI API.
Quelle différence entre RAG et la simple recherche vectorielle ?
La recherche vectorielle retrouve des documents, tandis que le RAG les utilise pour générer une réponse en langage naturel.